
Our Technology
The SML core Engine which is at the centre of our toolset and has evolved over 25 years to provide a set of meaningful automated tools
The process the FermaT toolset processes Assembler Language programs to produce Pseudocode is as follows:
The Assembler Language code is first parsed into our internal language WSL. The aim of this translation is to capture everything in the assembler program and express it within WSL. This will typically result in as many as two or three times the number of WSL statements as the original Assembler.
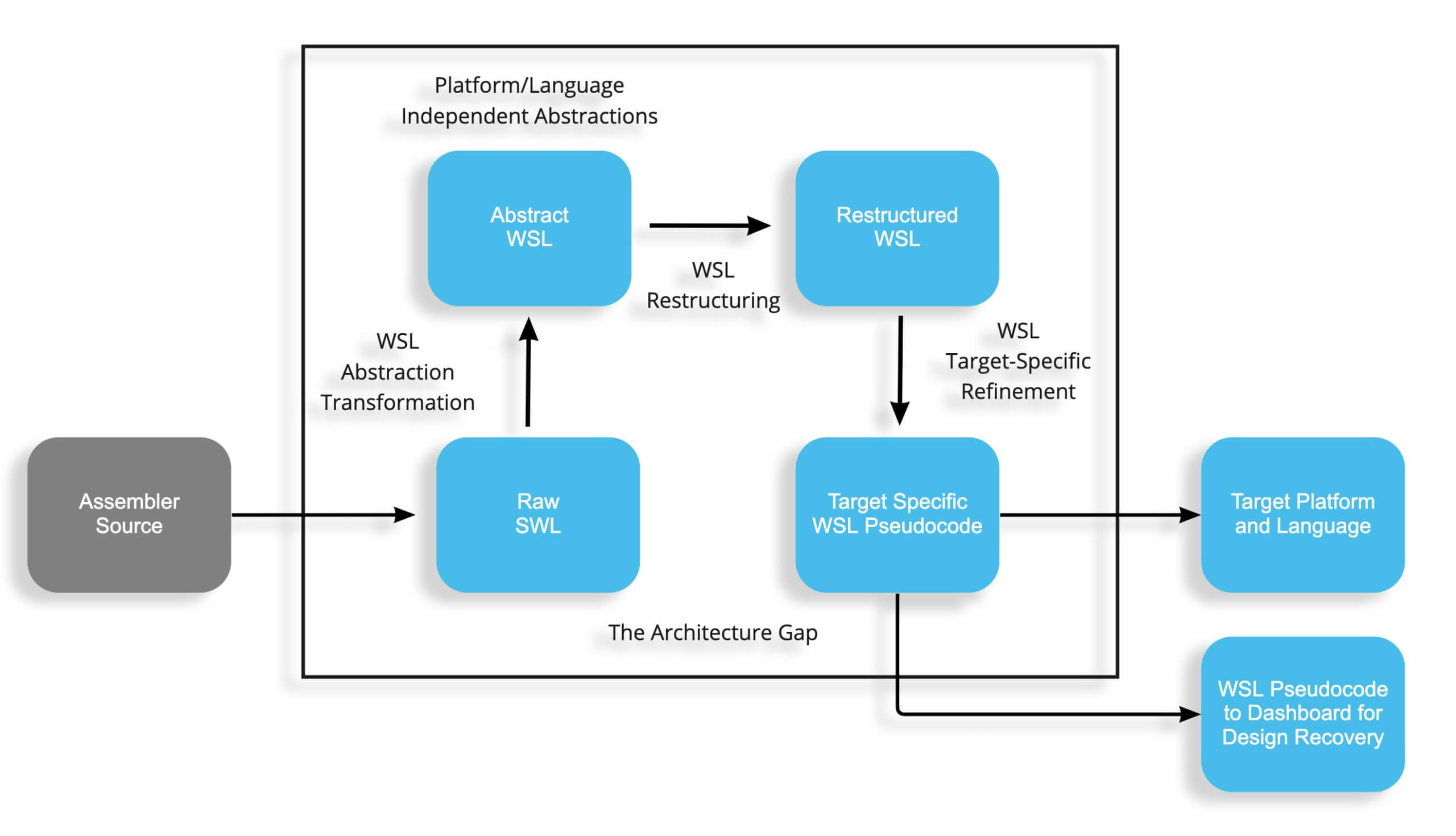
We now have what is referred to as Raw WSL. From this raw WSL, we apply program transformations to eliminate assembler specific features and abstract all of the processing in the code into a refined WSL. At this point, the Abstract WSL is now separate from, but functionally equivalent to the original Assembler.
The Abstract WSL is then processed into Restructured WSL. This is achieved by the automatic use of a set of Transformations that simplify and restructure the Restructured WSL code. These make extensive use of mathematical Transformation Theory Algorithms all of which are verifiable.
The end result is a set of structured, simplified, interconnected procedures which perform exactly the same functions as the original Assembler, but from which all of the inherent complexities of the Assembler Language have been removed. Typically several thousand transformations are applied automatically to each assembler module. Larger modules can take over 500,000 transformations. It is then possible to refine the WSL further to produce Target Specific WSL, for example for conversion to Cobol, C or Java or for use as Pseudocode where the objective is to re-engineer into more contemporary architecture and language.
In the case of Pseudocode, we provide two views of each program represented, a technical one and a business one. Again we stress that the Pseudocode contains exactly the same functionality as the original Assembler. This is then passed to our Dashboard System which provides a further set of tools to aid the process of re-engineering.
At the start of all migration projects, we measure the complexity of all of the original Assembler for all programs.
At the end of the migration process, we measure the complexity of the Pseudocode. In both cases, we use the McCabe Cyclomatic Complexity Metric which is widely used throughout the industry. Typically the complexity rating for the Pseudocode will be one-third of the complexity of the original Assembler.
It is still fully functionally equivalent to the original Assembler.
Re-Engineering Online Assembler Systems
Analysis and comprehension of the existing code base is critical to a successful re-engineering project. Even if documentation does exist, it is often out of date and incomplete, critical business rules only exist in the code and are not documented elsewhere. The only way to ensure equivalent functionality is by close analysis of the existing code to produce specifications for the new architected code base to be hosted on-prem or in the Cloud.
Legacy Assembler Systems offer unique challenges to achieving this understanding in: the complexity of the code itself (and limited available resources that understand it); the split of the execution path across many different modules (potentially thousands); and the less than transparent way in which Assembler programmes typically handle transient data between modules.
These challenges, taken together, can mean hundreds – even thousands – of man years of manual analysis to comprehend even a moderately sized installation. There is also the added challenge of ensuring the quality and consistency of this analysis across large teams.